Tutorial: Black Box Testing
What Is Testing?
Testing is a way to check if your software is running properly by purposefully trying to find errors so they can be corrected or prevented from happening in the future.
Why Should You Test?
One thing that’s important to understand is that software testing cannot prevent all bugs or errors. Instead, it can identify bugs and errors so they can be corrected. If testing is used in conjunction with software development it can quickly and easily identify when and where new changes to the software have caused issues or problems so they may be corrected. However, since testing uses a specific set of conditions to test with, it will not cover all cases and prevent all bugs — but it can often prevent introducing new bugs for those specific conditions when new or additional software changes are made.
Downsides of Testing?
This is kind of a glass half full, glass half empty question. While testing is helpful in finding bugs it is also a tedious process and it cannot prevent all bugs from occurring. In addition, good testing conditions are hard to establish especially with highly complex and multi-variable software.
Black Box Testing
Tests the input and outputs of the software and focuses on the software behavior and it’s performance efficiency. In black box testing there is no knowledge of how the internal system works, only that when given an input you get the correct output.
| Tester Inputs -> | Software (internals unknown) |
-> Software Outputs |
Equivalence Partitioning
Test conditions are divided into groups of functionality that exhibit similar behaviors. Instead of testing the functionality individually, which may take a long time, you can test one section of functionality from the group because the other functionality is likely to exhibit the same behavior given the same conditions.

In the image above you can see an example of equivalence partitioning. Each 9 block square of the Sudoku puzzle is a smaller component of code that behaviors similarly to the others. Therefore if we wrote an equivalence test to pass in a number to one of the boxes on the Sudoku board it would return true/false if a duplicate number was found in that section of the box. This test would work exactly the same way for the other colored partitions, therefore there’s no need to write a test for each of the individual partitions.
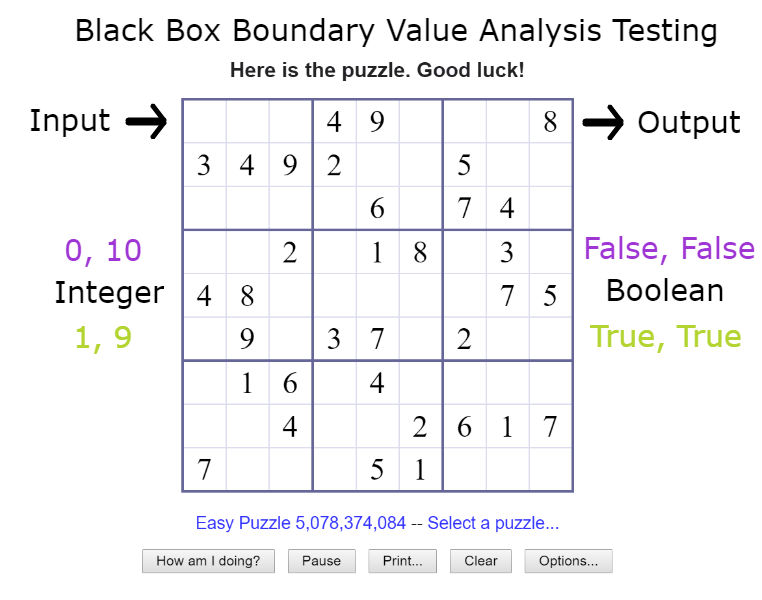
Boundary Value Analysis Testing
Often times a problem arises with a piece of software when the input value is at the boundary of the acceptable input values. With boundary value testing you identify the valid and input partitions and then test the high and low values of that boundary.
Let’s go back to our original Sudoku puzzle. In this game we allow the numbers 1-9 in each of the squares. That means numbers below 1 and above 9 are invalid. So we can separate our input partition into three partitions, two invalid and one valid:
In this case we test the value before and right after the ends of our valid partitions. That means testing 0 and 1 and then 9 and 10.

Another approach to boundary testing is to only test the upper and lower values of the valid partition and the upper and lower boundaries of the invalid partitions. For example, testing to make sure 0, 10 are invalid and 1,9 are valid.
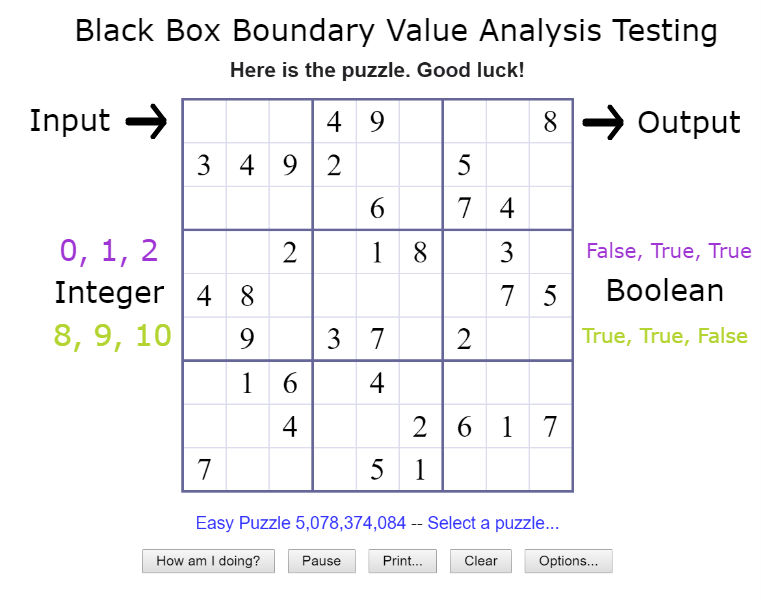
Another way to boundary test is to include one number after the boundary and one number before the boundary, as well as the boundary itself. That would mean testing 0, 1, 2 where 1 is the lower boundary and 8, 9, 10 where 9 is the upper boundary.
Decision Table Testing
This allows you to take a complex rule set and and translate it to it’s corresponding actions. Each rule goes in the top section of the table and each action goes in the bottom. Then you create a grid with different rules selected in the conditions section and the corresponding action that should happen when those conditions are met.
Let’s take our Sudoku for example and make a simple decision table for it.
| Conditions | Rules | |||||||
|---|---|---|---|---|---|---|---|---|
| User enters valid number | Y | Y | Y | Y | N | N | N | N |
| Duplicate number in that grid section | Y | Y | N | N | Y | Y | N | N |
| Grid has no more empty spaces | Y | N | Y | N | Y | N | Y | N |
| Actions | ||||||||
| Highlight the grid square | X | X | X | X | X | X | ||
| Validate the user input | X | X | X | X | X | X | X | X |
| Check for duplicate numbers | X | X | X | X | X | X | X | X |
| Show an error | X | X | X | X | X | X | ||
| Check for a winning game | X | |||||||
In our decision table we added some of the possible game conditions and then outcomes we expect if those conditions are or are not met. Now we can test our game for each of these conditions and assert that the predicted outcomes have been met successfully.
State Transition Table Testing
This table uses the different states of the software and what they should transition to in order to develop tests. First you start with a state diagram, then you translate that into a state transition table. Let’s continue with our Sudoku example where we have a few major states of the game: drawing the board, validating input, showing an error message, checking to see if the game is won or not, handling a winning game, showing a final score and then clearing the board to start a new game.

To make our state transition table we put our state down one column and user inputs across the top rows. Then we fill in the table according to the input to indicate what states the software can transition to once the input is given. So, when Sudoku validates the user’s input after they enter a number it will either find valid input and check the game status to see if they won, or it will recognize an invalid or duplicate input and show them an error message.
|
Input
State
|
Enter A Number | Press Clear | Submit Score |
|---|---|---|---|
| Draw Board | Validate Input | Clear Board | |
| Validate Input | Check Game Status | ||
| Validate Input | Show Error Message | ||
| Show Error Message | Draw Board | ||
| Clear Board | Draw Board | ||
| Show Score | Draw Board | ||
| Check Game Status | Draw Board | ||
| Check Game Status | Game Over | ||
| Game Over | Show Score |
Use Case Testing
This kind of testing approaches the different interactions that an actor will typically use in order to accomplish their goals when they are using the software. An actor is anyone who will be interacting with the software.

If we refer back to our Sudoku example we have only one actor, the person playing the game. Then we define all of the different goals our user will need to accomplish as it’s own use case. Now we can tailor our tests to ensure that all of these different use cases are present and working in the final version of our software.
Fuzz Testing
With fuzz testing you enter values that are outside of the expected input, as well as longer and shorter than the expected input.
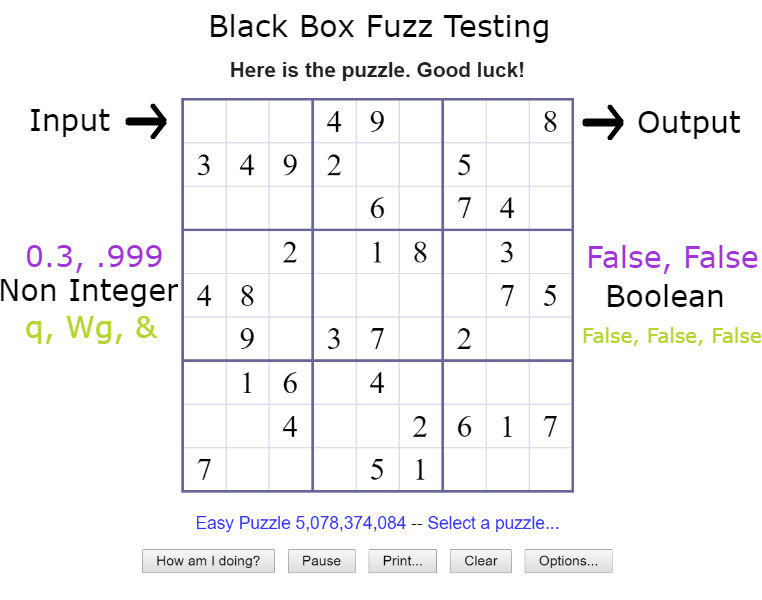 Since our Sudoku expects a single integer that means we would perform fuzz testing with non-integer values, as well as empty values and more than the maximum characters expected. In the example below we test floats, strings, characters and values with more than 1 character.
Since our Sudoku expects a single integer that means we would perform fuzz testing with non-integer values, as well as empty values and more than the maximum characters expected. In the example below we test floats, strings, characters and values with more than 1 character.
Exploratory Testing
This is a by-product of running other black box testing. As a tester, as you write tests for the software you will, by your own creativity, observation or personal experience, think of other good tests that you want to include during the testing of your software.
For instance, if you’re familiar with Cross Site Scripting Injections (XSS) and while you’re doing Fuzz testing you realize you can enter more than a single character into the Sudoku input box you may then decide to run additional XSS injection tests to make sure the software cannot be compromised in this way.
Grey Box Testing
This is just like black box testing except the tester does have some knowledge of the internal data structures or algorithms used in the software while they are running their black box tests. The tester may only have knowledge of the data structures or a limited access to the code base while they are performing their black box tests.
| Tester Inputs -> | Software (internals partially known) |
-> Software Outputs |
Testing In Practice
Generally you find three schools of thought when it comes to testing in a real development situation, each have their own reasons for using or not using tests.
No Testing
Testing is extremely time consuming and if you’re developing software that changes often and in a large way the tests you’ve written may not even be relevant anymore. For this reason in rapid development and prototyping you’re less likely to include any kind of testing.
Some Testing
This school of thought is that it’s good to have tests for your software but they don’t need to be exhaustive. Generally if you’re doing some testing you’ll set a threshold for the amount of testing you must have in order for the testing to be considered “good enough”. This is usually found in legacy software systems or systems that are so large and didn’t have tests before than adding in tests to the existing code base would be an enormous and/or exhaustive effort. These tend to be developers that recognize the benefit of testing however, they also realize that testing will not stop or prevent all bugs from ever happening and the software is changing fast enough that tests need not provide 100% coverage on the code base. Also, some things are much harder or impossible to test so achieving tests for 100% of the software may not be possible.
Test Driven Development
In this practice all tests are written before the code has been developed and the test should describe what the code will do. Generally in test driven development you don’t see a lot of documentation in the code base because the tests are representative of that documentation (or should be). Software created with test driven development tends to have fewer bugs but the amount of time invested on creating and modifying tests as the code base changes is a large part of the development cycle for the software. In addition, there are times when it’s impossible to test a piece of code that’s been written which leaves you to question if the code should be re-designed or the test needs to be re-written causing a lot of circling back during the development process.